

Efficient AI
Блок 2. Нейронные сети. Ускорение нейронных сетей

Где мы?
- Вводная
- Блок 1
- Блок 2
- 1 мая
- 9 мая
- Блок 3
- Экзамен
Содержание
- Как ускоряют инференс?
- Как ускоряют тренировку?
Как усоряют инференс?
- Меньше модель
- Быстрее вычислитель
Как уменьшить модель?
- Размер модели
- Тип данных
Как ускорить вычислитель?
- Hardware-friendly вычисления
- Системные оптимизации
Уменьшаяем модель: дистилляция знаний
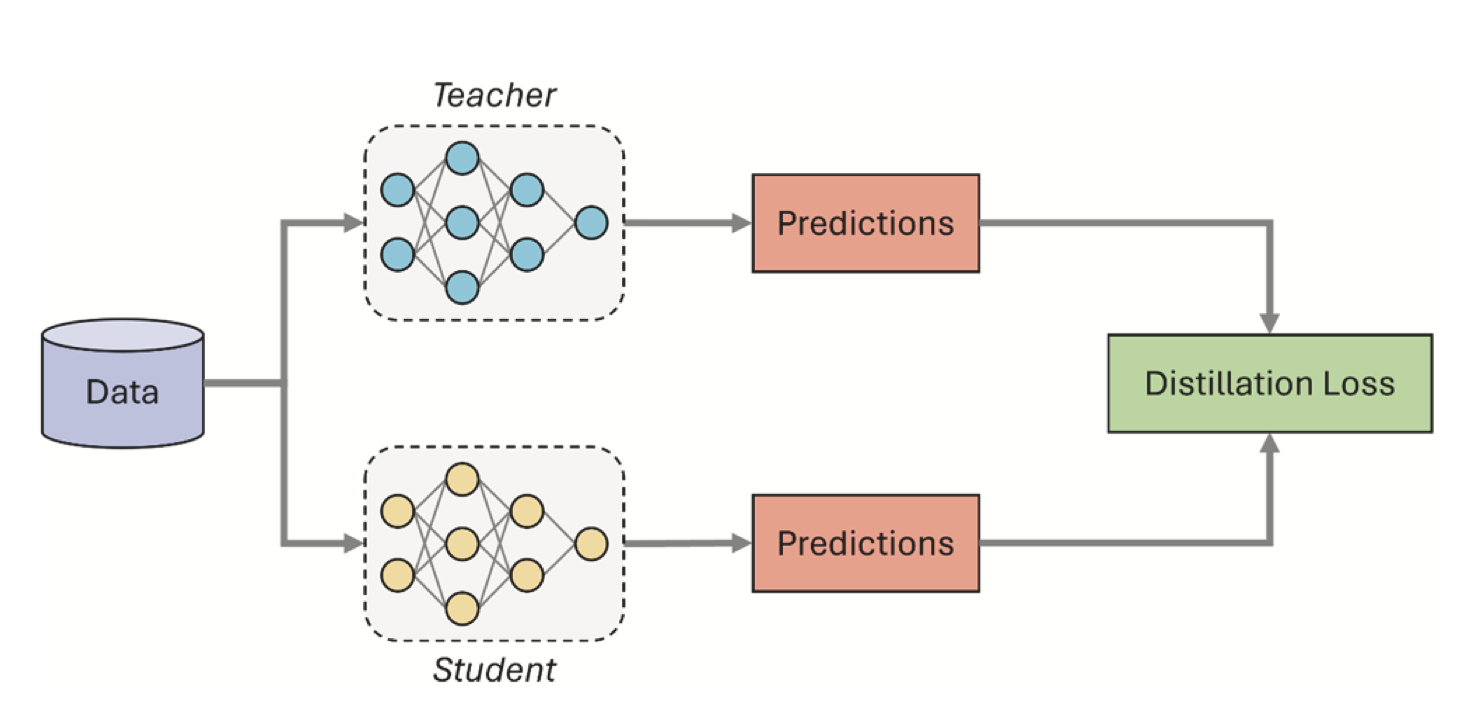
Уменьшаяем модель: дистилляция знаний
$$ L = \alpha L_{KL} + \beta L_{CE} + \gamma L_{MSE} + \delta L_{entropy} $$
Уменьшаяем модель: прунинг и разрежённость
- Структурный прунинг
- Полуструктурный прунинг
- Неструктурный прунинг
Уменьшаяем модель: прунинг и разрежённость
$$ \min_{w} L(D, W \odot M) \text{ при } ||M||_0 \le k $$
Уменьшаяем модель: прунинг и разрежённость
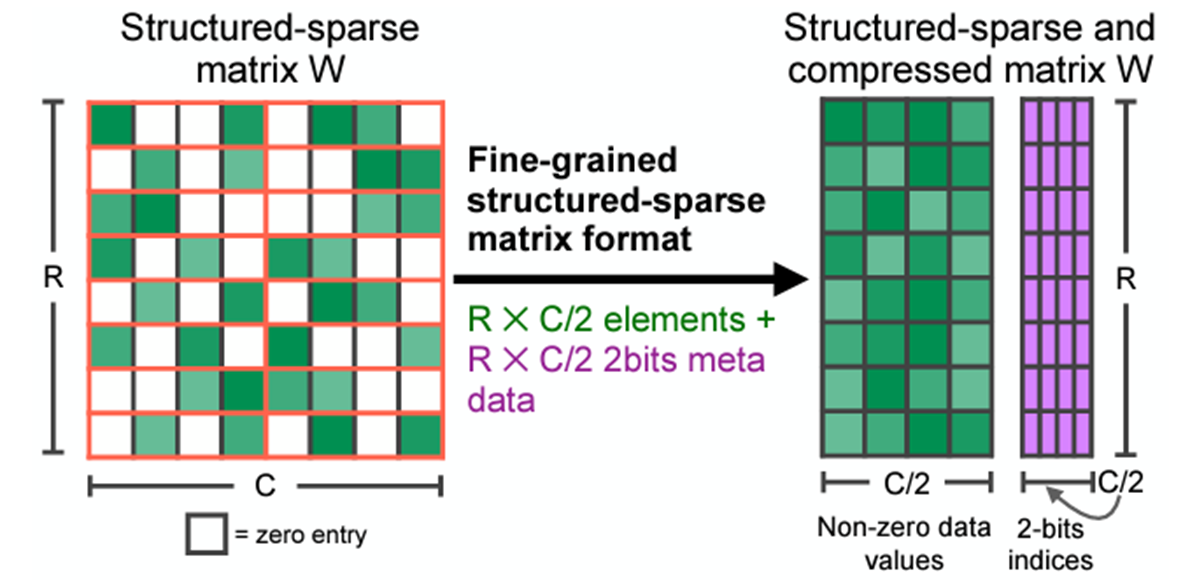
Уменьшаяем модель: компактные числа с плавающей точкой

Уменьшаяем модель: целые числа и квантизация
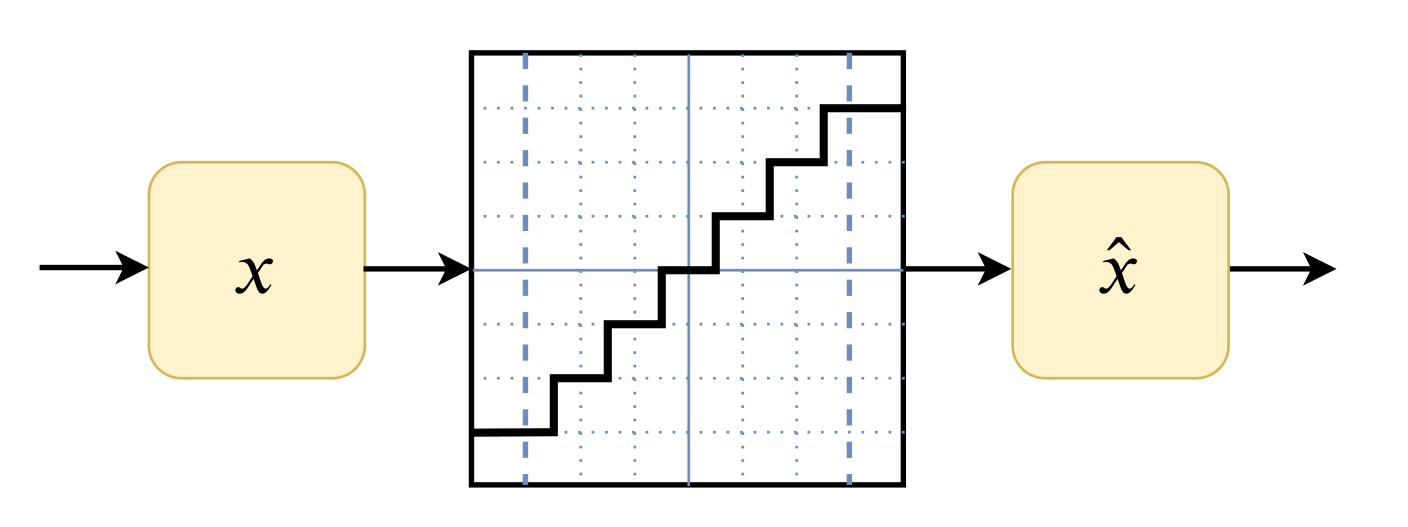
Уменьшаяем модель: целые числа и квантизация
$$ x_q = \text{int}\left(\frac{x}{s}\right) - z $$
$$ x_{d} = s (x_q + z) $$
$$ s = \frac{\beta - \alpha}{2^{n} - 1} $$
Уменьшаяем модель: целые числа и квантизация
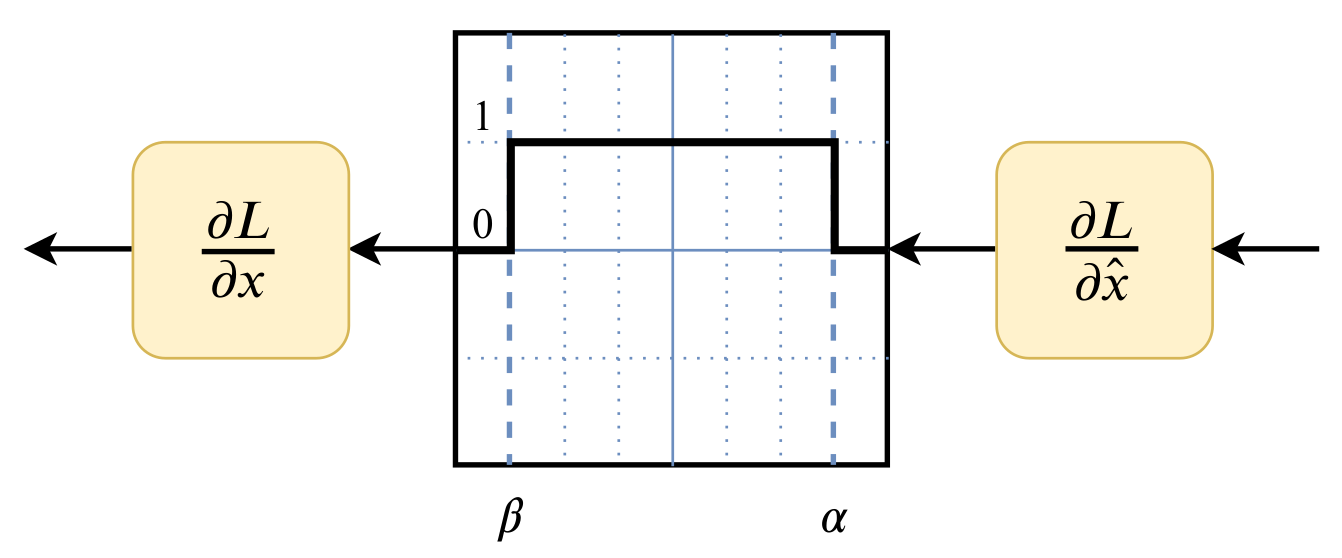
Уменьшаяем модель: аппроксимация
Перерыв
Ускоряем тренировку: чекпоинтинг градиентов
Ускоряем тренировку: параллелизм
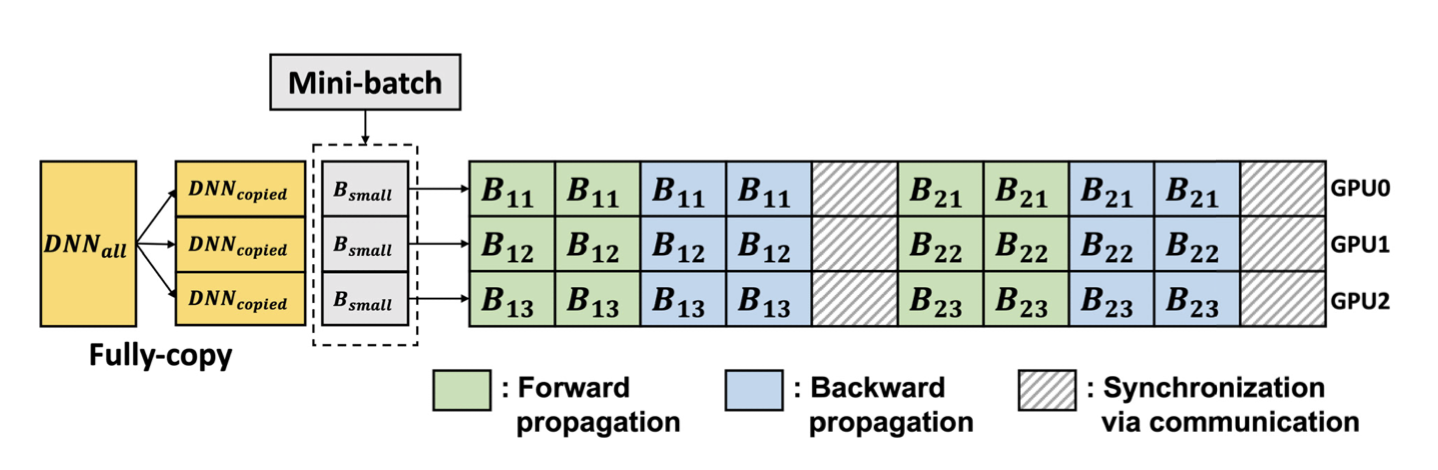
Data-параллелизм
Ускоряем тренировку: параллелизм
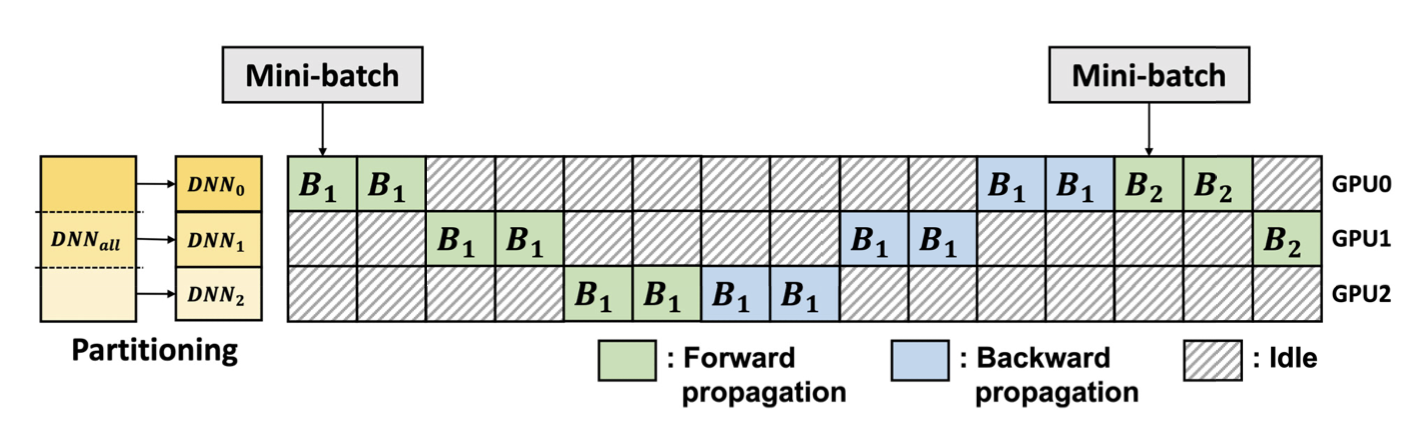
Model-параллелизм
Ускоряем тренировку: параллелизм
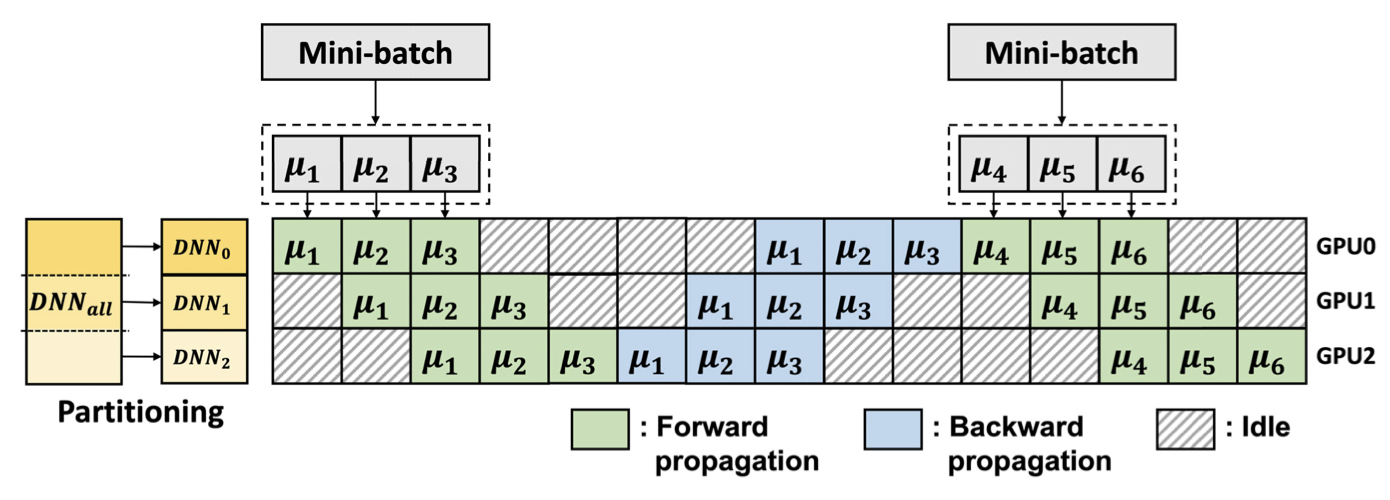
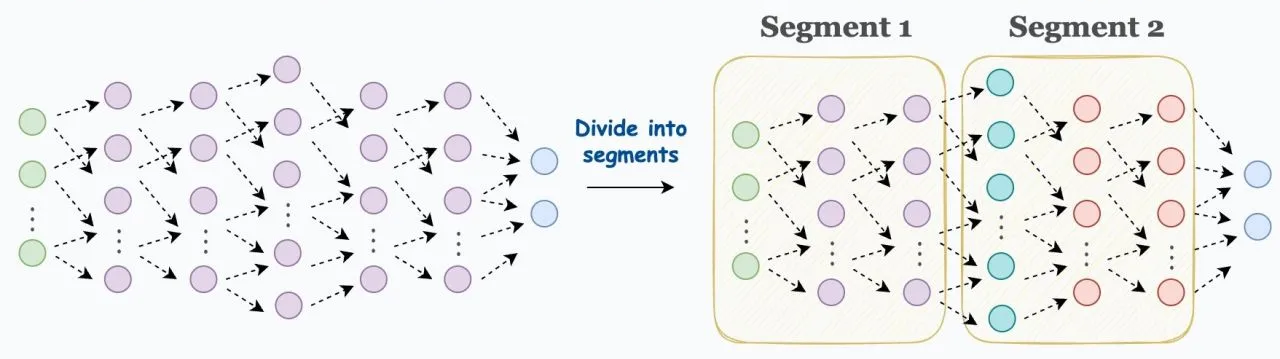
Pipeline-параллелизм
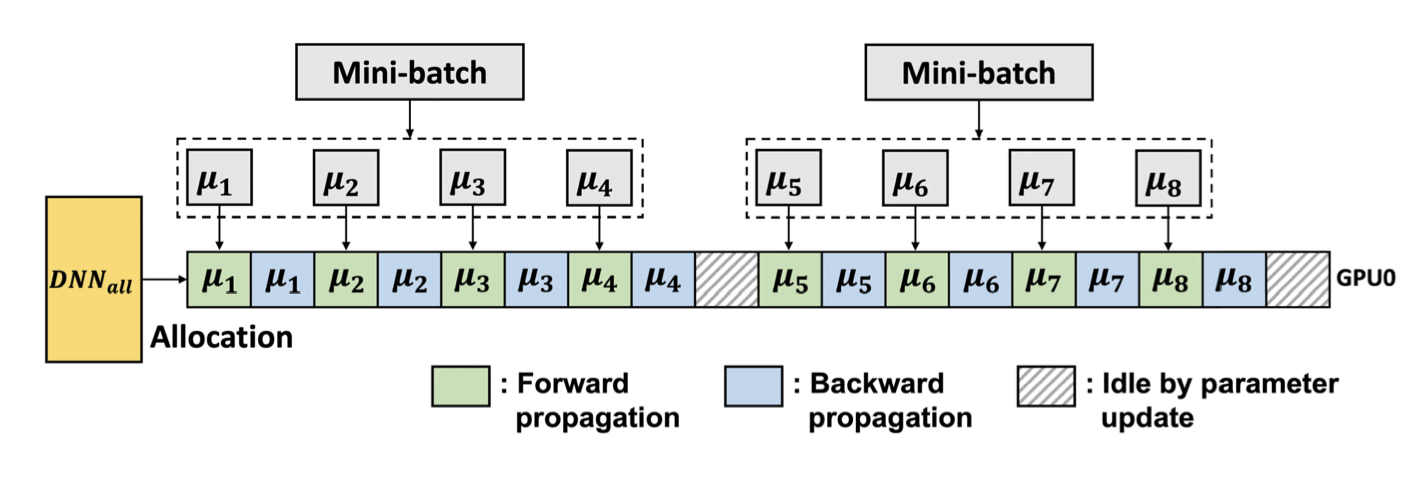
Ускоряем тренировку: микробатчи
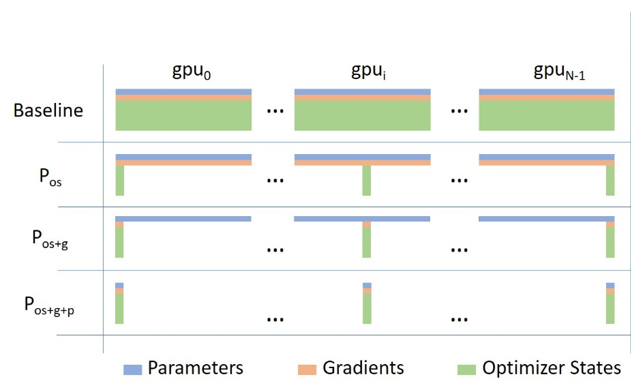
Ускоряем тренировку: шардирование от Microsoft aka ZeRO
Ускоряем тренировку: эффективный fine-tuning
