Efficient AI
Блок 3. Языковые модели. Оптимизации трансформеров

Где мы?
- Вводная
- Блок 1
- Блок 2
- 1 мая
- 9 мая
- Блок 3
- Экзамен
Содержание
- Вспоминаем узкие места
- Оптимизации данных
- Оптимизации модели
- Оптимизации системы
Узкие места
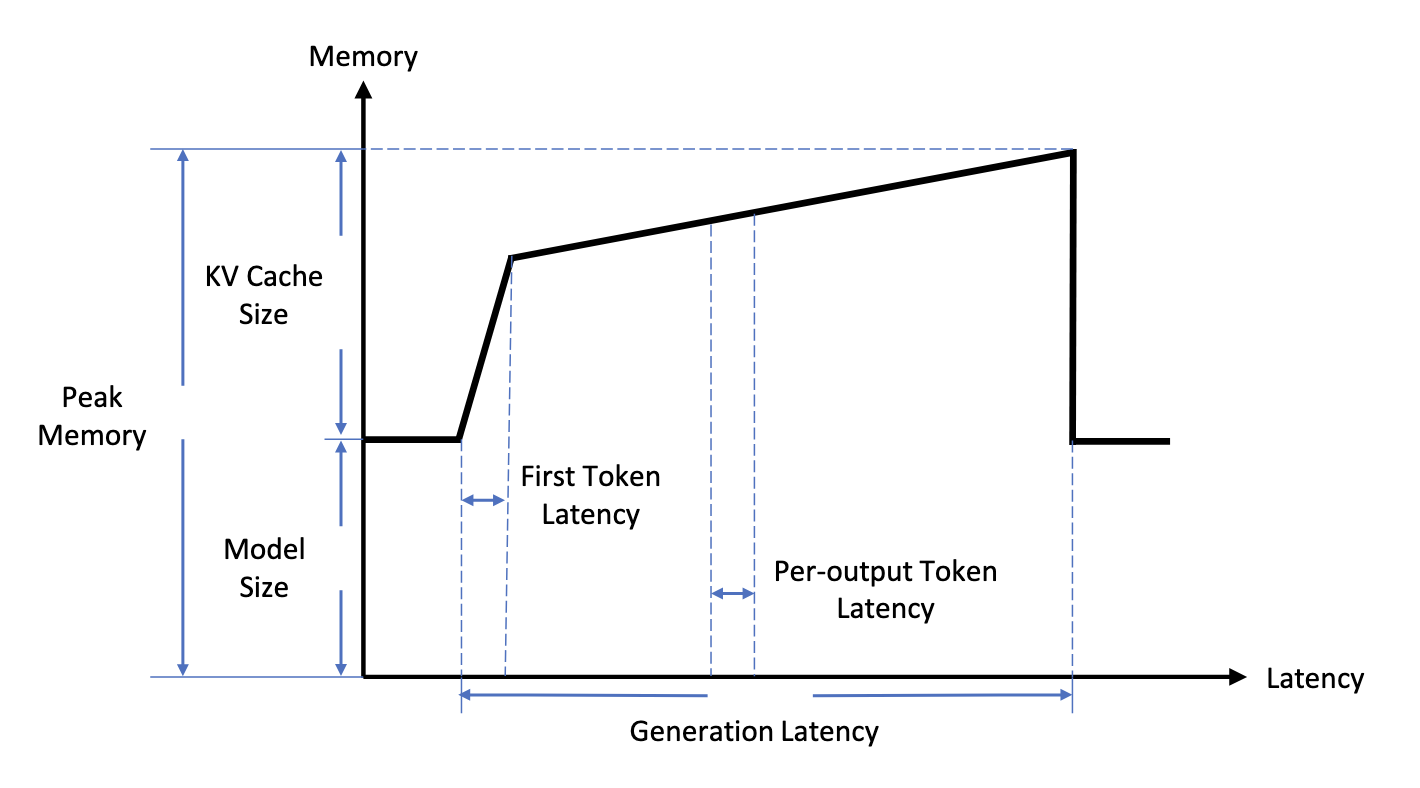
Память
Входные и выходные данные
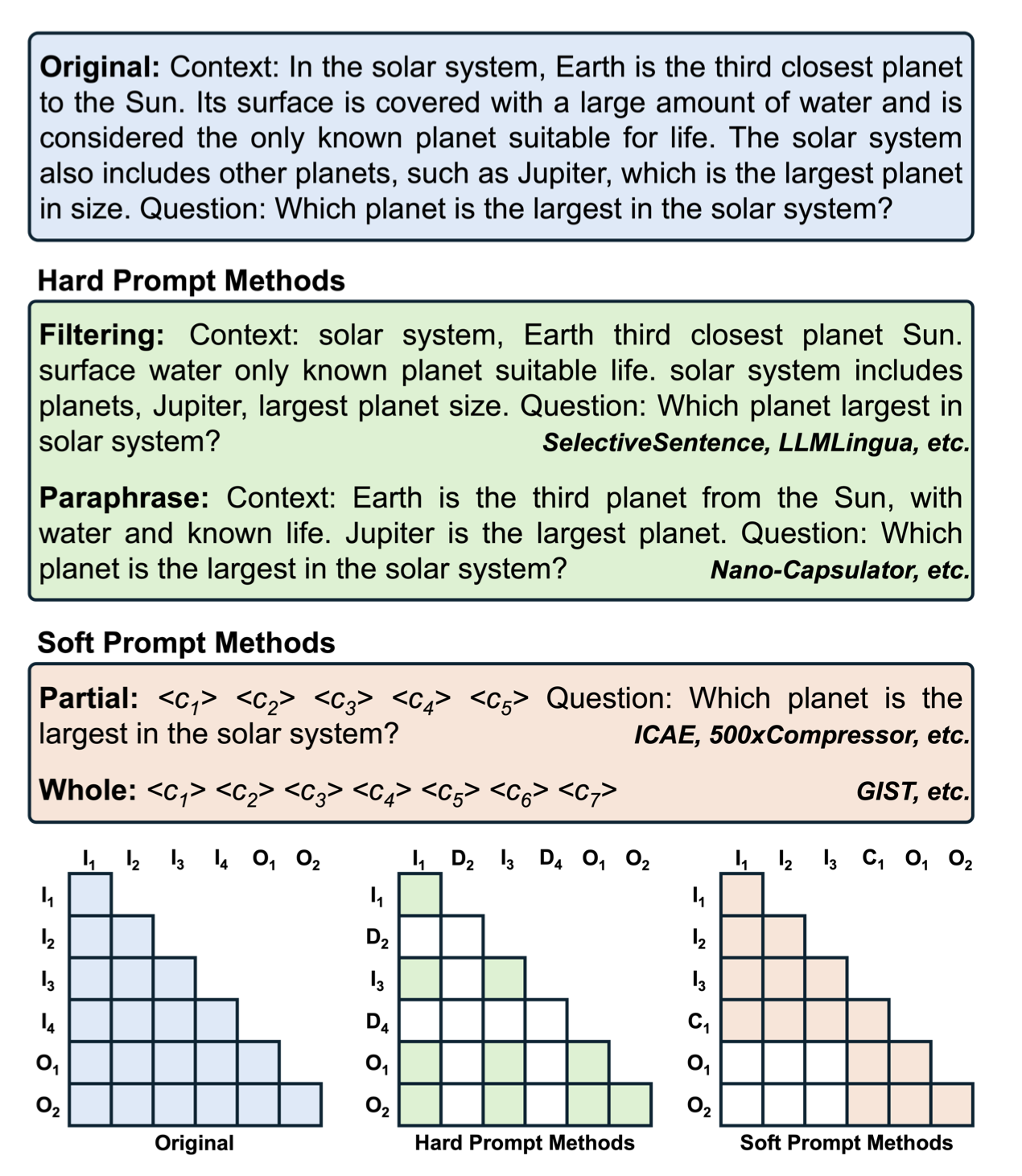
- Pruning
- Summarization
- Soft prompt Compression
- RAG
- Output Organization
Входные данные
Выходные данные
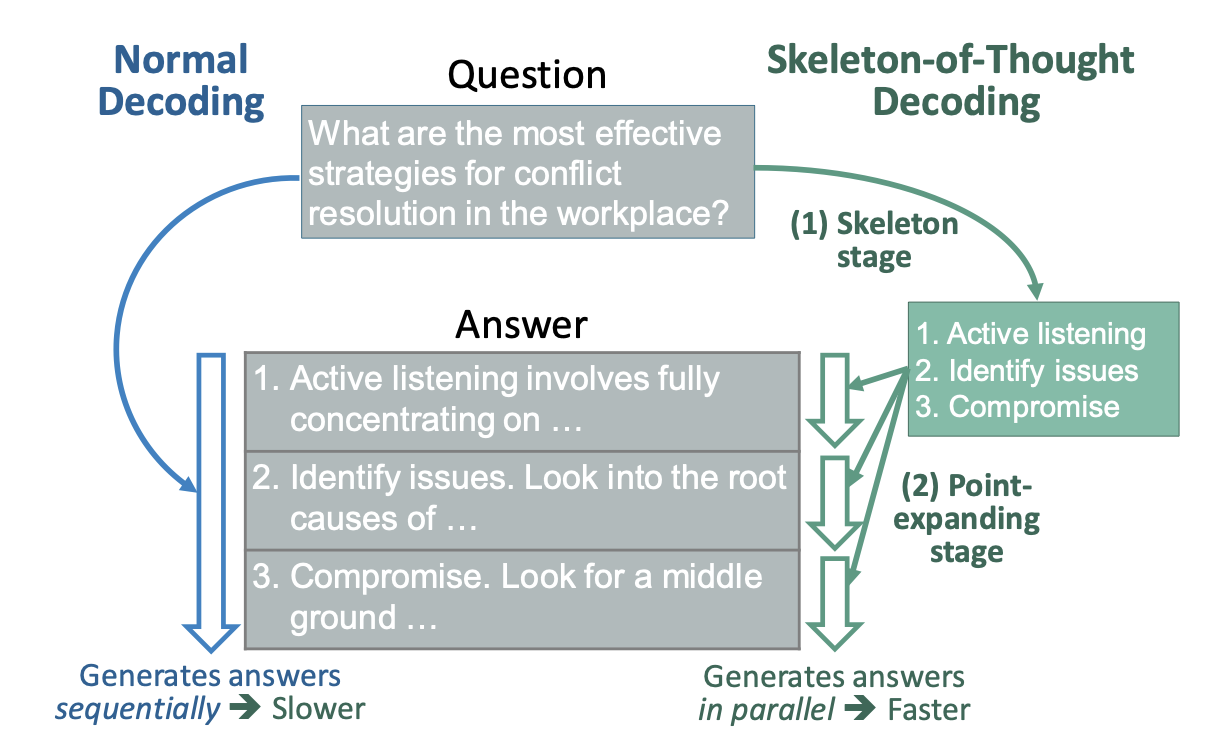
Выходные данные
Перерыв
Модель
- FFN: MoE и MoEfication
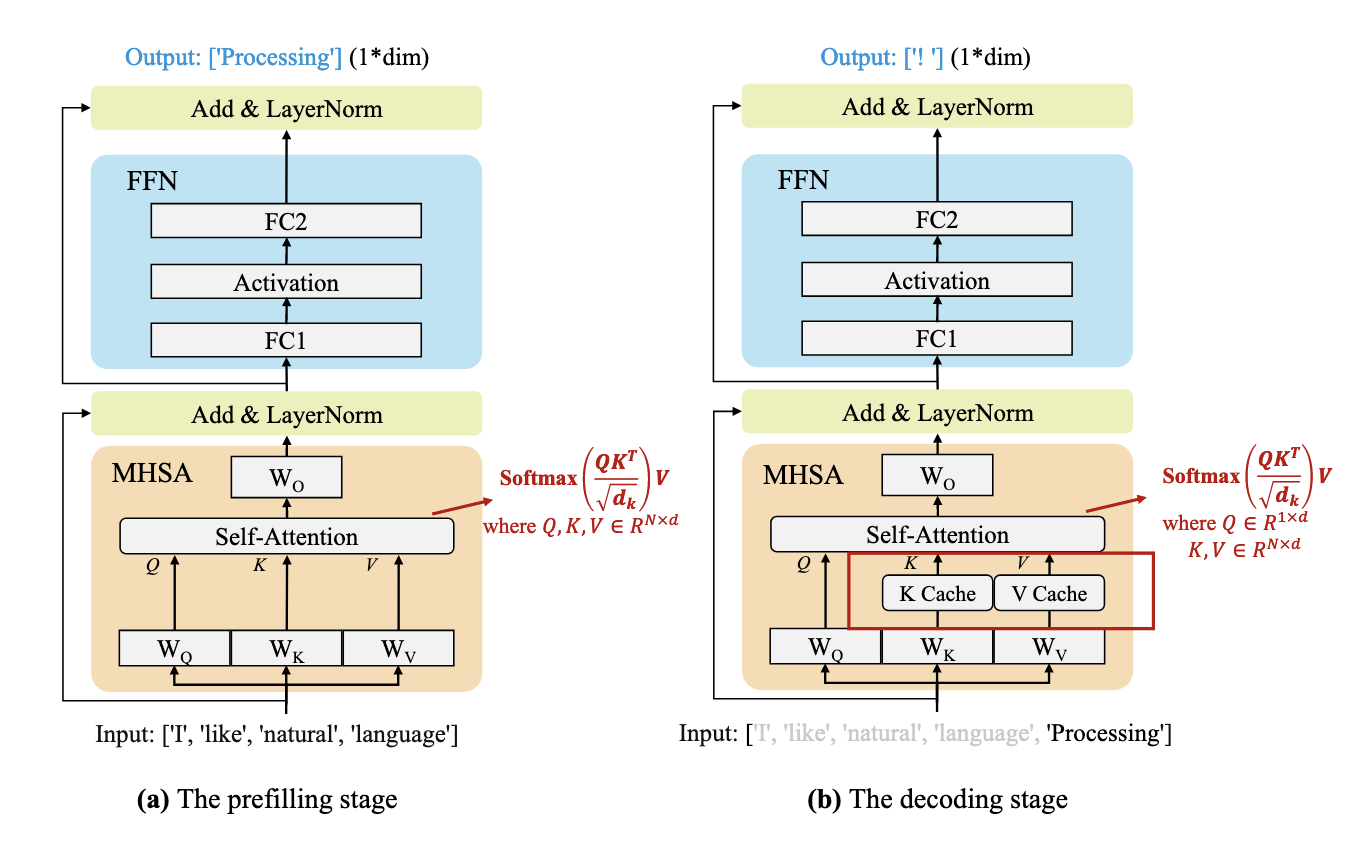
- Attention: KV Cache
- Attention: Linearization
- Attention: Low-Rank
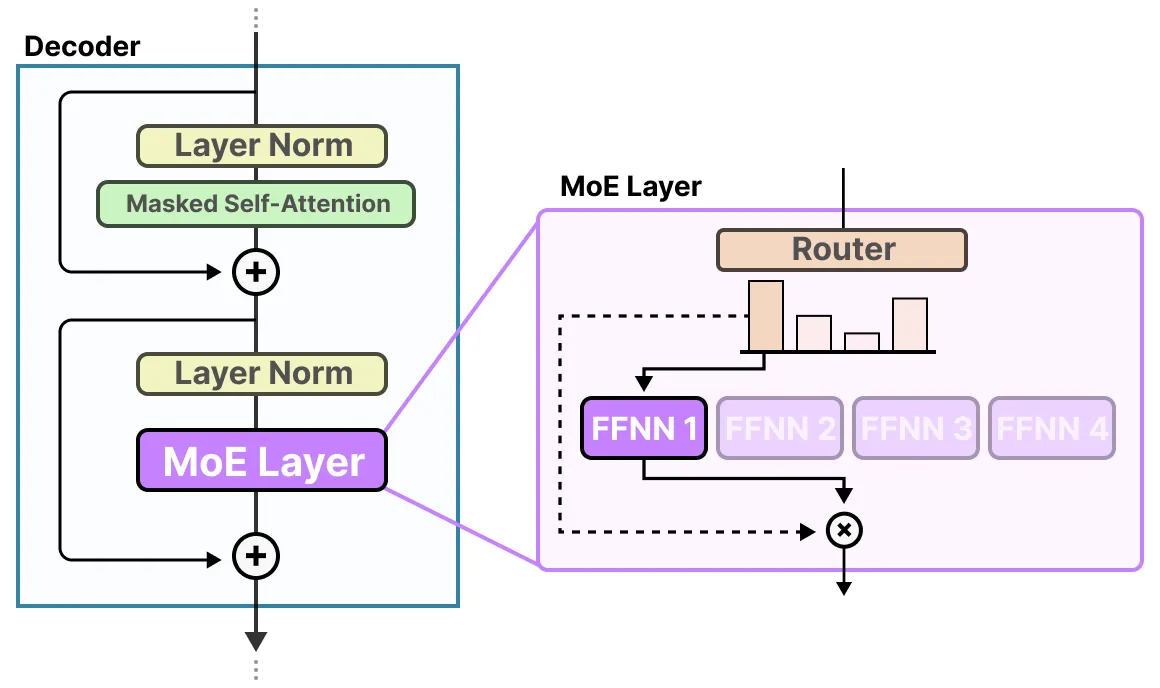
Mixture-of-Experts
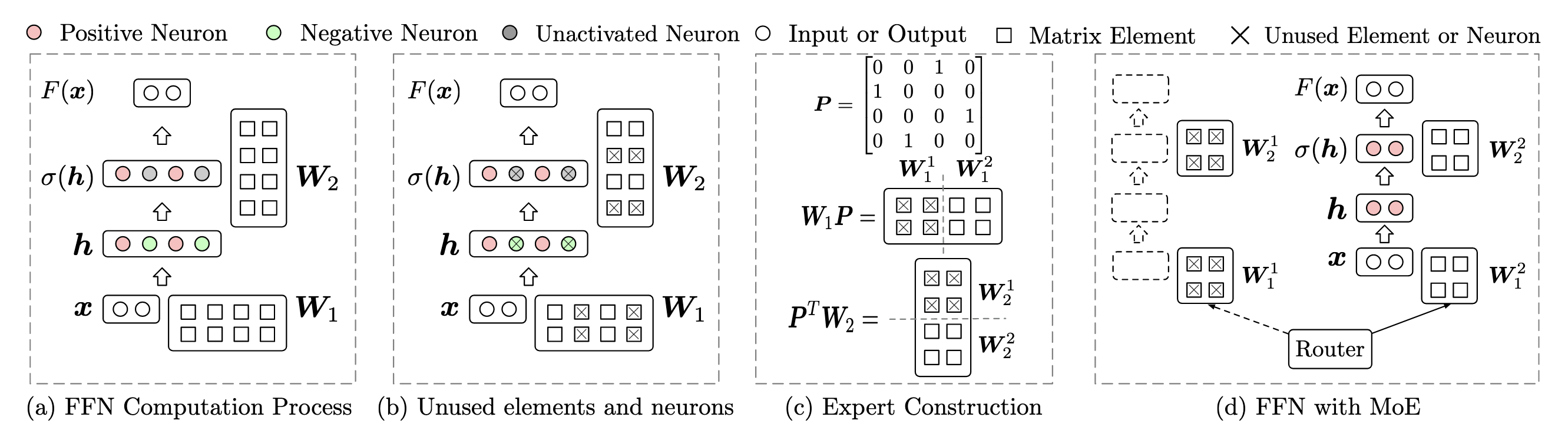
MoEfication
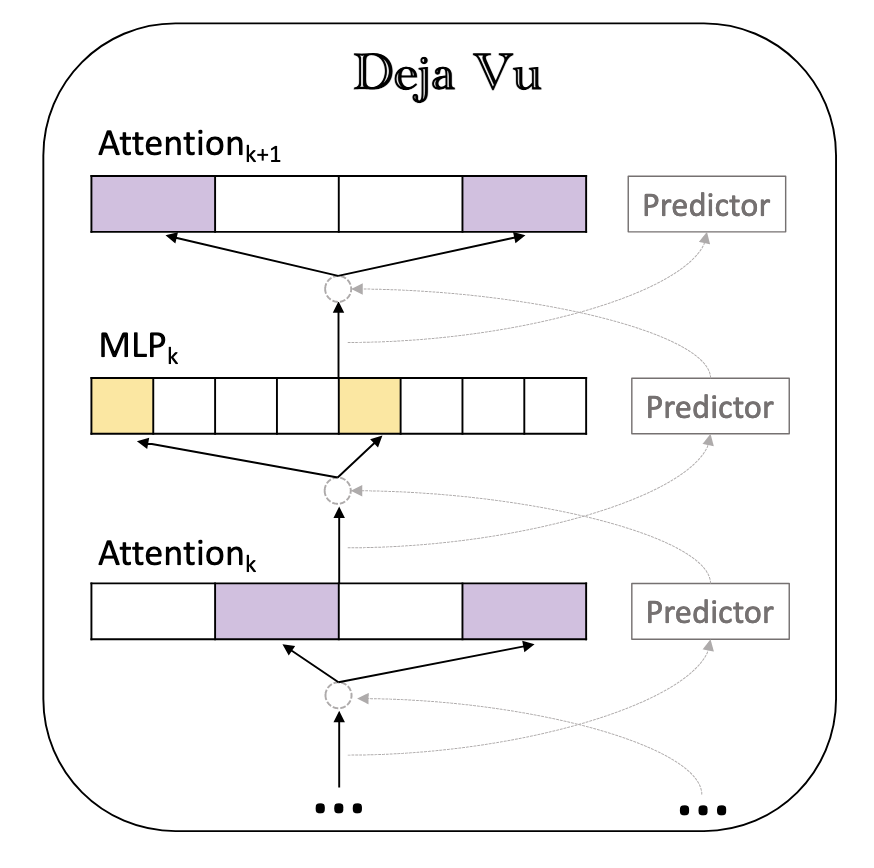
Deja Vu
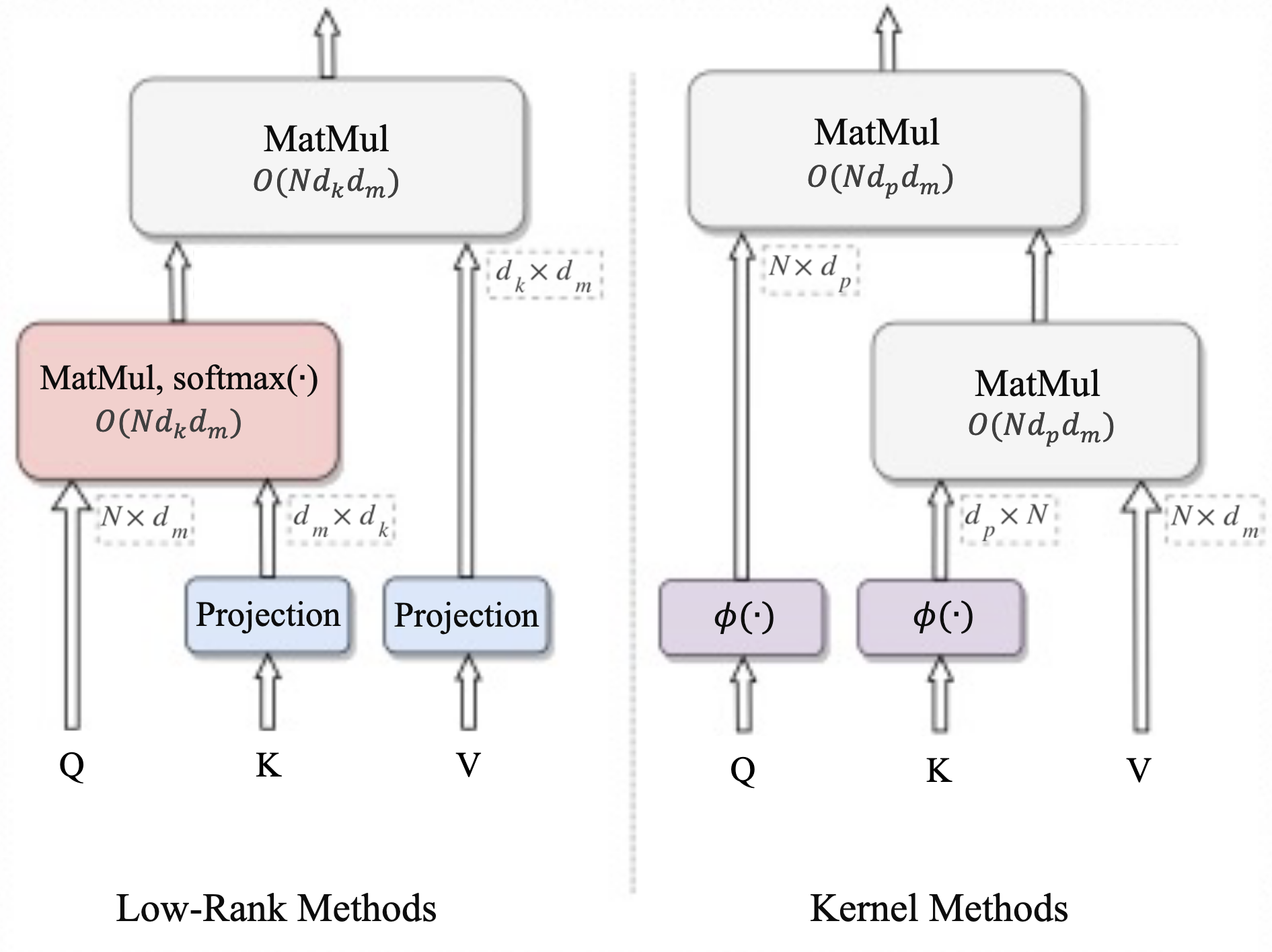
Attention
Система
- Непрерывный батчинг
- Спекулятивный декодинг
- Hardware-friendly computing
Непрерывный батчинг